
Blog
2020-07-29
A week ago, it was 22 July: Pi Approximation Day.
22/7 (22 July in DD/M format) is very close to pi, closer in fact than 14 March's
approximation of 3.14 (M.DD).
During this year's Pi Approximation Day, I was wondering if there are other days that give good
approximations of interesting numbers. In particular, I wondered if there is a good 2π (or τ)
approximation day.
π is close to 22/7, so 2π is close to 44/7—but sadly there is no 44th July.
The best approximation day for 2π is 25th April, but 25/4 (6.25) isn't really close to
2π (6.283185...) at all. The day after Pi Approximation Day, however, is a good approximation of 2π-3 (as π-3 is
approximately 1/7). After noticing this, I realised that the next day would be a good approximation
of 3π-6, giving a nice run of days in July that closely approximate expressions involving pi.
After I tweeted about these three, Peter Rowlett suggested
that I could get a Twitter bot to do the work for me. So I made one:
@HappyApproxDay.
Since writing this post, Twitter broke @HappyApproxDay by changing their API, but the bot lives on on
Mathstodon (@HappyApproxDay@mathstodon.xyz)
and Bluesky (@happyapproxday.bsky.social).
@HappyApproxDay is currently looking for days that approximate expressions involving
π, τ, e, √2 and √3, and approximate the chosen expression better than
any other day of the year. There are an awful lot of ways to combine these numbers, so @HappyApproxDay@mathstodon.xyz
looks like it might be tooting quite a lot...
Edit: Added Mastodon and Bluesky links
(Click on one of these icons to react to this blog post)
You might also enjoy...



Comments
Comments in green were written by me. Comments in blue were not written by me.
⭐ top comment (2020-07-30) ⭐
June the 28th (6.28) isn't too bad for 2 Pi.steve
Add a Comment
2020-05-03
This is a post I wrote for The Aperiodical's Big Lock-Down Math-Off. You can vote for (or against) me here until 9am on Tuesday...
A few years ago, I made @mathslogicbot (now relocated to @logicbot@mathstodon.xyz and @logicbot.bsky.social), a Twitter bot that tweets logical tautologies.
The statements that @mathslogicbot tweets are made up of variables (a to z) that can be either true or false, and the logical symbols
\(\lnot\) (not), \(\land\) (and), \(\lor\) (or), \(\rightarrow\) (implies), and \(\leftrightarrow\) (if and only if), as well as brackets.
A tautology is a statement that is always true, whatever values are assigned to the variables involved.
To get an idea of how to interpret @mathslogicbot's statements, let's have a look at a few tautologies:
\(( a \rightarrow a )\). This says "a implies a", or in other words "if a is true, then a is true". Hopefully everyone agrees that this is an always-true statement.
\(( a \lor \lnot a )\). This says "a or not a": either a is true, or a is not true
\((a\leftrightarrow a)\). This says "a if and only if a".
\(\lnot ( a \land \lnot a )\). This says "not (a and not a)": a and not a cannot both be true.
\(( \lnot a \lor \lnot \lnot a )\). I'll leave you to think about what this one means.
(Of course, not all statements are tautologies. The statement \((b\land a)\), for example, is not a tautology as is can be true or false depending on the
values of \(a\) and \(b\).)
While looking through @mathslogicbot's tweets, I noticed that a few of them are interesting, but most are downright rubbish.
This got me thinking: could I get rid of the bad tautologies like these, and make a list of just the "interesting" tautologies. To do this, we first need to
think of different ways tautologies can be bad.
Looking at tautologies the @mathslogicbot has tweeted, I decided to exclude:
- tautologies like \((a\rightarrow\lnot\lnot\lnot\lnot a)\) that contain more than one \(\lnot\) in a row.
- tautologies like \(((a\lor\lnot a)\lor b)\) that contain a shorter tautology. Instead, tautologies like \((\text{True}\lor b)\) should be considered.
- tautologies like \(((a\land\lnot a)\rightarrow b)\) that contain a shorter contradiction (the opposite of a tautology). Instead, tautologies like \((\text{False}\rightarrow b)\) should be considered.
- tautologies like \((\text{True}\lor\lnot\text{True})\) or \(((b\land a)\lor\lnot(b\land a)\) that are another tautology (in this case \((a\lor\lnot a)\)) with a variable replaced with something else.
- tautologies containing substatements like \((a\land a)\), \((a\lor a)\) or \((\text{True}\land a)\) that are equivalent to just writing \(a\).
- tautologies that contain a \(\rightarrow\) that could be replaced with a \(\leftrightarrow\), because it's more interesting if the implication goes both ways.
- tautologies containing substatements like \((\lnot a\lor\lnot b)\) or \((\lnot a\land\lnot b)\) that could be replaced with similar terms (in these cases \((a\land b)\) and \((a\lor b)\) respectively) without the \(\lnot\)s.
- tautologies that are repeats of each other with the order changed. For example, only one of \((a\lor\lnot a)\) and \((\lnot a\lor a)\) should be included.
After removing tautologies like these, some of my favourite tautologies are:
- \(( \text{False} \rightarrow a )\)
- \(( a \rightarrow ( b \rightarrow a ) )\)
- \(( ( \lnot a \rightarrow a ) \leftrightarrow a )\)
- \(( ( ( a \leftrightarrow b ) \land a ) \rightarrow b )\)
- \(( ( ( a \rightarrow b ) \leftrightarrow a ) \rightarrow a )\)
- \(( ( a \lor b ) \lor ( a \leftrightarrow b ) )\)
- \(( \lnot ( ( a \land b ) \leftrightarrow a ) \rightarrow a )\)
- \(( ( \lnot a \rightarrow b ) \leftrightarrow ( \lnot b \rightarrow a ) )\)
You can find a list of the first 500 "interesting" tautologues here. Let me know on Twitter
which is your favourite. Or let me know which ones you think are rubbish, and we can further refine the list...
Edit: Added Mastodon and Bluesky links
(Click on one of these icons to react to this blog post)
You might also enjoy...
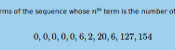


Comments
Comments in green were written by me. Comments in blue were not written by me.
Add a Comment
2016-10-08
During my Electromagnetic Field talk this year, I spoke about @mathslogicbot (now reloated to @logicbot@mathstodon.xyz and @logicbot.bsky.social), my Twitter bot that is working its way through the tautologies in propositional calculus. My talk included my conjecture that the number of tautologies of length \(n\) is an increasing sequence (except when \(n=8\)). After my talk, Henry Segerman suggested that I also look at the number of contradictions of length \(n\) to look for insights.
A contradiction is the opposite of a tautology: it is a formula that is False for every assignment of truth values to the variables. For example, here are a few contradictions:
$$\neg(a\leftrightarrow a)$$
$$\neg(a\rightarrow a)$$
$$(\neg a\wedge a)$$
$$(\neg a\leftrightarrow a)$$
The first eleven terms of the sequence whose \(n\)th term is the number of contradictions of length \(n\) are:
$$0, 0, 0, 0, 0, 6, 2, 20, 6, 127, 154$$
This sequence is A277275 on OEIS. A list of contractions can be found here.
For the same reasons as the sequence of tautologies, I would expect this sequence to be increasing. Surprisingly, it is not increasing for small values of \(n\), but I again conjecture that it is increasing after a certain point.
Properties of the sequences
There are some properties of the two sequences that we can show. Let \(a(n)\) be the number of tautolgies of length \(n\) and let \(b(n)\) be the number of contradictions of length \(n\).
First, the number of tautologies and contradictions, \(a(n)+b(n)\), (A277276) is an increasing sequence. This is due to the facts that \(a(n+1)\geq b(n)\) and \(b(n+1)\geq a(n)\), as every tautology of length \(n\) becomes a contraction of length \(n+1\) by appending a \(\neg\) to be start and vice versa.
This implies that for each \(n\), at most one of \(a\) and \(b\) can be decreasing at \(n\), as if both were decreasing, then \(a+b\) would be decreasing. Sadly, this doesn't seem to give us a way to prove the conjectures, but it is a small amount of progress towards them.
Edit: Added Mastodon and Bluesky links
(Click on one of these icons to react to this blog post)
You might also enjoy...


Comments
Comments in green were written by me. Comments in blue were not written by me.
Add a Comment
2015-03-15
A few months ago, I set
@mathslogicbot (and @logicbot@mathstodon.xyz and @logicbot.bsky.social) going on the
long task of tweeting all the tautologies (containing 140 characters or less)
in propositional calculus with the symbols \(\neg\) (not), \(\rightarrow\)
(implies), \(\leftrightarrow\) (if and only if), \(\wedge\) (and) and \(\vee\)
(or). My first post on logic bot contains a full
explanation of propositional calculus, formulae and tautologies.
An alternative method
Since writing the original post, I have written an alternative script to
generate all the tautologies.
In this new method, I run through all possible strings of length 1 made
with character in the logical language, then strings of length 2, 3 and so on.
The script then checks if they are valid formulae and, if so, if they are
tautologies.
In the new script, only formulae where the first appearances of variables
are in alphabetical order are considered. This means that duplicate tautologies
are removed. For example, \((b\rightarrow(b\wedge a))\) will now be counted as
it is the same as \((a\rightarrow(a\wedge b))\).
You can view or download this alternative code on
github.
All the terms of the sequence that I have calculated so far can be viewed
here and the tautologies for these terms are
here.
Sequence
One advantage of this method is that it generates the tautologies sorted by
the number of symbols they contain, meaning we can generate the sequence whose
\(n\)th term is the number of tautologies of length \(n\).
The first ten terms of this sequence are
$$0, 0, 0, 0, 2, 2, 12, 6, 57, 88$$
as there are no tautologies of length less than 5; and, for example two
tautologies of length 6 (\((\neg a\vee a)\) and \((a\vee \neg a)\)).
This sequence is listed as
A256120 on OEIS.
Properties
There are a few properties of this sequence that can easily be shown.
Throughout this section I will use \(a_n\) to represent the \(n\)th
term of the sequence.
Firstly, \(a_{n+2}\geq a_n\). This can be explained as follows: let \(A\)
be a tautology of length \(n\). \(\neg\neg A\) will be of length \(n+2\) and
is logically equivalent to \(A\).
Another property is \(a_{n+4}\geq 2a_n\): given a tautology \(A\) of length
\(n\), both \((a\vee A)\) and \((A\vee a)\) will be tautologies of length
\(n+4\). Similar properties could be shown for \(\rightarrow\),
\(\leftrightarrow\) and \(\wedge\).
Given properties like this, one might predict that the sequence will be
increasing (\(a_{n+1}\geq a_n\)). However this is not true as \(a_7\) is 12
and \(a_8\) is only 6. It would be interesting to know at how many points in
the sequence there is a term that is less than the previous one. Given the
properties above it is reasonable to conjecture that this is the only one.
Edit: The sequence has been published on OEIS!
Edit: Added Mastodon and Bluesky links
(Click on one of these icons to react to this blog post)
You might also enjoy...
Comments
Comments in green were written by me. Comments in blue were not written by me.
Great project! Would be interesting to have a version of this for the sheffer stroke. ×3 ×3 ×3 ×1 ×3
×3 ×3 ×3 ×1 ×3
om
Add a Comment
2014-11-26
Last week, @mathslogicbot (also now on Mastodon (@logicbot@mathstodon.xyz) and Bluesky (@logicbot.bsky.social)) started the long task of tweeting every tautology in propositional calculus. This post explains what this means and how I did it.
What is propositional calculus?
Propositional calculus is a form of mathematical logic, in which the formulae (the logical 'sentences') are made up of the following symbols:
- Variables (a to z and \(\alpha\) to \(\lambda\)) (Variables are usually written as \(p_1\), \(p_2\), etc. but as Twitter cannot display subscripts, I chose to use letters instead.)
- Not (\(\neg\))
- Implies (\(\rightarrow\))
- If and only if (\(\leftrightarrow\))
- And (\(\wedge\))
- Or (\(\vee\))
- Brackets (\(()\))
Formulae
Formulae are defined recursively using the following rules:
- Every variable is a formula.
- If \(A\) is a formula, then \(\neg A\) is a formula.
- If \(A\) and \(B\) are formulae then \((A\rightarrow B)\), \((A\leftrightarrow B)\), \((A\wedge B)\) and \((A\vee B)\) are all formulae.
For example, \((a\vee b)\), \(\neg f\) and \(((a\vee b)\rightarrow\neg f)\) are formulae.
Each of the variables is assigned a value of either "true" or "false", which leads to each formula being either true or false:
- \(\neg a\) is true if \(a\) is false (and false otherwise).
- \((a\wedge b)\) is true if \(a\) and \(b\) are both true (and false otherwise).
- \((a\vee b)\) is true if \(a\) or \(b\) is true (or both are true) (and false otherwise).
- \((a\leftrightarrow b)\) is true if \(a\) and \(b\) are either both true or both false (and false otherwise).
- (\(a \rightarrow\ b)\) is true if \(a\) and \(b\) are both true or \(a\) is false (and false otherwise).
Tautologies
A tautology is a formula that is true for any assigment of truth values to the variables. For example:
\((a\vee \neg a)\) is a tautology because: if \(a\) is true then \(a\) or \(\neg a\) is true; and if \(a\) is false, then \(\neg a\) is true, so \(a\) or \(\neg a\) is true.
\((a\leftrightarrow a)\) is a tautology because: if \(a\) is true then \(a\) and \(a\) are both true; and if \(a\) is false then \(a\) and \(a\) are both false.
\((a\wedge b)\) is not a tautology because if \(a\) is true and \(b\) is false, then it is false.
The following are a few more tautologies. Can you explain why they are always true?
- \((a\leftrightarrow a)\)
- \(((a\vee\neg a)\vee a)\)
- \(\neg(a\wedge\neg a)\)
- \((a\vee(a\rightarrow b))\)
Python
If you want to play with the Logic Bot code, you can download it here.
In order to find all tautologies less than 140 characters long, one method is to first generate all formulae less than 140 characters then check to see if they are tautologies. (This is almost certainly not the fastest way to do this, but as long as it generates tautolgies faster than I want to tweet them, it doesn't matter how fast it runs.) I am doing this on a Raspberry Pi using Python in the following way.
All formulae
The following code is writing all the formulae that are less than 140 characters to a file called formulae.
python
from os.path import joinpath = "/home/pi/logic"
First import any modules needed and set the path where the file will be saved.
python
def candidate(formula):global formulae
if len(formula) <= 140 and formula not in formulae:
formulae.append(formula)
print formula
f = open(join(path,"formulae"),"a")
f.write(formula + "\n")
f.close()
This function checks that a formula is not already in my list of formulae and shorter than 140 characters, then adds it to the list and writes it into the file.
python
variables = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j","k", "l", "m", "n", "o", "p", "q", "r", "s", "t",
"u", "v", "w", "x", "y", "z", "@", "#", "2", "3",
"4", "5", "6", "7", "8", "9"]
This line says which characters are going to be used as variables. It is impossible to write a formula in less that 140 characters with more than 36 different variables so these will be sufficient. I haven't used 0 and 1 as these are used to represent false and true later.
python
f = open(join(path,"formulae"))formulae = f.readlines()
for i in range(0,len(formulae)):
formulae[i] = formulae[i].strip("\n")
f.close()
These lines load the formulae already found from the file. This is needed if I have to stop the code then want to continue.
python
oldlen = 0newlen = 26
while oldlen != newlen:
for f in formulae + variables:
candidate("-" + f)
for f in formulae + variables:
for g in formulae:
for star in ["I", "F", "N", "U"]:
candidate("(" + f + star + g + ")")
oldlen = newlen
newlen = len(formulae)
The code inside the while loop goes through every formula already found and puts "-" in front of it, then takes every pair of formulae already found and puts "I", "F", "N" or "U" between them. These characters are used instead of the logical symbols as using the unicode characters leads to numerous python errors. The candidate function as defined above then adds them to the list (if they are suitable). This continues until the loop does not make the list of formulae longer as this will occur when all formulae are found.
python
f = open(join(path,"formulae"),"a")f.write("#FINISHED#")
f.close()
Once the loop has finished this will add the string "#FINISHED#" to the file. This will tell the truth-checking code when the it has checked all the formulae (opposed to having checked all those generated so far).
Tautologies
Now that the above code is finding all formulae, I need to test which of these are tautologies. This can be done by checking whether every assignment of truth values to the variables will lead to the statement being true.
python
from os.path import joinpath = "/home/pi/logic"
First import any modules needed and set the path where the file will be saved.
python
def next(ar,i=0):global cont
if i < len(ar):
if ar[i] == "0":
ar[i] = "1"
else:
ar[i] = "0"
ar = next(ar, i + 1)
else:
cont = False
return ar
Given an assignment of truth values, this function will return the next assignment, setting cont to False if all the assignments have been tried.
python
def solve(lo):lo = lo.replace("-0", "1")
lo = lo.replace("-1", "0")
lo = lo.replace("(0I0)", "1")
lo = lo.replace("(0I1)", "1")
lo = lo.replace("(1I0)", "0")
lo = lo.replace("(1I1)", "1")
lo = lo.replace("(0F0)", "1")
lo = lo.replace("(0F1)", "0")
lo = lo.replace("(1F0)", "0")
lo = lo.replace("(1F1)", "1")
lo = lo.replace("(0N0)", "0")
lo = lo.replace("(0N1)", "0")
lo = lo.replace("(1N0)", "0")
lo = lo.replace("(1N1)", "1")
lo = lo.replace("(0U0)", "0")
lo = lo.replace("(0U1)", "1")
lo = lo.replace("(1U0)", "1")
lo = lo.replace("(1U1)", "1")
return lo
This function will replace all instances of "NOT TRUE" with "FALSE" and so on. It will be called repeatedly until a formula is reduced to true or false.
python
f = open(join(path,"formulae"))formulae = f.readlines()
f.close()
f = open(join(path,"donet"))
i = int(f.read())
f.close()
variables = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j",
"k", "l", "m", "n", "o", "p", "q", "r", "s", "t",
"u", "v", "w", "x", "y", "z", "@", "#", "2", "3",
"4", "5", "6", "7", "8", "9"]
These lines read the formulae from the file they are saved in and load how many have been checked if this script has been restarted. The the variables are set.
python
while formulae[-1] != "#FINISHED#" or i < len(formulae) - 1:if i < len(formulae):
formula = formulae[i].strip("\n")
These lines will loop through all formulae until "#FINISHED#" is reached.
python
insofar = TrueinA = []
fail = False
for a in variables:
if a not in formula:
insofar = False
elif not insofar:
fail = True
break
else:
inA.append(a)
Here, the code checks that if a variable is in the formula, then all the previous variables are in the formula. This will prevent the Twitter bot from repeating many tautologies that are the same except for the variable a being replaced by b (although there will still be some repeats like this. Can you work out what these will be?).
python
if not fail:valA = ["0"]*len(inA)
cont = True
taut = True
while cont and taut:
feval = formula
for j in range(0,len(inA)):
feval = feval.replace(inA[j],valA[j])
while feval not in ["0", "1"]:
feval = solve(feval)
if feval != "1":
taut = False
valA = next(valA)
if taut:
f = open(join(path,"true"),"a")
f.write(str(formula) + "\n")
f.close()
i += 1
f = open(join(path,"donet"),"w")
f.write(str(i))
f.close()
Now, the formula is tested to see if it is true for every assignment of truth values. If it is, it is added to the file containing tautologies. Then the number of formulae that have been checked is written to a file (in case the script is stopped then resumed).
python
else:f = open(join(path,"formulae"))
formulae = f.readlines()
f.close()
If the end of the formulae file is reached, then the file is re-loaded to include all the formulae found while this code was running.
Tweeting
Finally, I wrote a code that tweets the next item in the file full of tautologies every three hours (after replacing the characters with the correct unicode characters).
How long will it take?
Now that the bot is running, it is natural to ask how long it will take to tweet all the tautologies.
While it is possible to calculate the number of formulae with 140 characters or less, there is no way to predict how many of these will be tautologies without checking. However, the bot currently has over 13 years of tweets lines up. And all the tautologies so far are under 30 characters so there are a lot more to come...
Edit: Updated time left to tweet.
Edit: Added Mastodon and Bluesky links
(Click on one of these icons to react to this blog post)
You might also enjoy...
Comments
Comments in green were written by me. Comments in blue were not written by me.
In part two you say a_{n+4} >= 2*a_n, and you have 13 years worth of tweets of length (say) 15-30. so there are 26 years worth length 19-34 characters, 13*2^n years worth of tweets of length between (15 + 4n) and (30 + 4n). In particular, setting n = 27, we have 13*2^{27} = 1744830464 years worth of tweets of length 123-138. I hope you have nice sturdy hardware!
×3 ×3 ×3 ×3 ×3
Christian
Add a Comment