
Blog
2015-03-03
This post explains how to make a trihexaflexagon with and images you like on the three
faces.
Making the template
To make a flexagon template with your images on, visit mscroggs.co.uk/flexagons. On this page, you will be
able to choose three images (png, jp(e)g or gif) which will appear on the faces of your flexagon.
Once you have created the template, save and print the image it gives you.
The template may fail to load if your images are too large; so if your template doesn't
appear, resize your images and try again.
Making the flexagon
First, cut out your printed tempate. For this example, I used plain blue, green and purple
images.
)
Then fold and glue your template in half lengthways.
)
Next, fold diagonally across the blue diamond, being careful to line the fold up with the purple
diamond. This will bring two parts of the purple picture together.
)
Do the same again with the blue diamond which has just been folded into view.
)
Fold the green triangle under the purple.
)
And finally tuck the white triangle under the purple triangle it is covering. This will bring the
two white triangles into contact. Glue these white triangles together and you have made a
flexagon.
)
Flexing the flexagon
Before flexing the flexagon, fold it in half through each pair of corners. This will get it
ready to flex in the right places.
)
Now fold your flexagon into the following position.
)
Then open it out from the centre to reveal a different face.
)
This video shows how to flex a
flexagon in more detail.
(Click on one of these icons to react to this blog post)
You might also enjoy...


Comments
Comments in green were written by me. Comments in blue were not written by me.
Add a Comment
2015-01-31
This is the third post in a series of posts about tube map folding.
In 2012, I folded all the Platonic solids from tube maps. The dodecahedron I made was a little dissapointing:
)
After my talk at Electromegnetic Field 2014, I was shown the following better method to fold a dodecahedron.
Making the modules
First, take a tube map, cut apart all the pages and cut each page in half.
)
Next, take one of the parts and fold it into four
)
then lay it flat.
)
Next, fold the bottom left corner upwards
)
and the top right corner downwards.
)
Finally, fold along the line shown below.
)
You have now made a module which will make up one edge of the dodecahedron. You will need 30 of these to make the full solid.
)
Putting it together
Once many modules have been made, then can be put together. To do this, tuck one of the corners you folded over into the final fold of another module.
)
Three of the modules attached like this will make a vertex of the dodecahedron.
)
By continuing to attach modules, you will get the shell of a dodecahedron.
)
To make the dodecahedron look more complete, fold some more almost-squares of tube map to be just larger than the holes and tuck them into the modules.
)
Previous post in series

This is the third post in a series of posts about tube map folding.
Next post in series

(Click on one of these icons to react to this blog post)
You might also enjoy...


Comments
Comments in green were written by me. Comments in blue were not written by me.
Add a Comment
2014-11-26
Last week, @mathslogicbot (also now on Mastodon (@logicbot@mathstodon.xyz) and Bluesky (@logicbot.bsky.social)) started the long task of tweeting every tautology in propositional calculus. This post explains what this means and how I did it.
What is propositional calculus?
Propositional calculus is a form of mathematical logic, in which the formulae (the logical 'sentences') are made up of the following symbols:
- Variables (a to z and \(\alpha\) to \(\lambda\)) (Variables are usually written as \(p_1\), \(p_2\), etc. but as Twitter cannot display subscripts, I chose to use letters instead.)
- Not (\(\neg\))
- Implies (\(\rightarrow\))
- If and only if (\(\leftrightarrow\))
- And (\(\wedge\))
- Or (\(\vee\))
- Brackets (\(()\))
Formulae
Formulae are defined recursively using the following rules:
- Every variable is a formula.
- If \(A\) is a formula, then \(\neg A\) is a formula.
- If \(A\) and \(B\) are formulae then \((A\rightarrow B)\), \((A\leftrightarrow B)\), \((A\wedge B)\) and \((A\vee B)\) are all formulae.
For example, \((a\vee b)\), \(\neg f\) and \(((a\vee b)\rightarrow\neg f)\) are formulae.
Each of the variables is assigned a value of either "true" or "false", which leads to each formula being either true or false:
- \(\neg a\) is true if \(a\) is false (and false otherwise).
- \((a\wedge b)\) is true if \(a\) and \(b\) are both true (and false otherwise).
- \((a\vee b)\) is true if \(a\) or \(b\) is true (or both are true) (and false otherwise).
- \((a\leftrightarrow b)\) is true if \(a\) and \(b\) are either both true or both false (and false otherwise).
- (\(a \rightarrow\ b)\) is true if \(a\) and \(b\) are both true or \(a\) is false (and false otherwise).
Tautologies
A tautology is a formula that is true for any assigment of truth values to the variables. For example:
\((a\vee \neg a)\) is a tautology because: if \(a\) is true then \(a\) or \(\neg a\) is true; and if \(a\) is false, then \(\neg a\) is true, so \(a\) or \(\neg a\) is true.
\((a\leftrightarrow a)\) is a tautology because: if \(a\) is true then \(a\) and \(a\) are both true; and if \(a\) is false then \(a\) and \(a\) are both false.
\((a\wedge b)\) is not a tautology because if \(a\) is true and \(b\) is false, then it is false.
The following are a few more tautologies. Can you explain why they are always true?
- \((a\leftrightarrow a)\)
- \(((a\vee\neg a)\vee a)\)
- \(\neg(a\wedge\neg a)\)
- \((a\vee(a\rightarrow b))\)
Python
If you want to play with the Logic Bot code, you can download it here.
In order to find all tautologies less than 140 characters long, one method is to first generate all formulae less than 140 characters then check to see if they are tautologies. (This is almost certainly not the fastest way to do this, but as long as it generates tautolgies faster than I want to tweet them, it doesn't matter how fast it runs.) I am doing this on a Raspberry Pi using Python in the following way.
All formulae
The following code is writing all the formulae that are less than 140 characters to a file called formulae.
python
from os.path import joinpath = "/home/pi/logic"
First import any modules needed and set the path where the file will be saved.
python
def candidate(formula):global formulae
if len(formula) <= 140 and formula not in formulae:
formulae.append(formula)
print formula
f = open(join(path,"formulae"),"a")
f.write(formula + "\n")
f.close()
This function checks that a formula is not already in my list of formulae and shorter than 140 characters, then adds it to the list and writes it into the file.
python
variables = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j","k", "l", "m", "n", "o", "p", "q", "r", "s", "t",
"u", "v", "w", "x", "y", "z", "@", "#", "2", "3",
"4", "5", "6", "7", "8", "9"]
This line says which characters are going to be used as variables. It is impossible to write a formula in less that 140 characters with more than 36 different variables so these will be sufficient. I haven't used 0 and 1 as these are used to represent false and true later.
python
f = open(join(path,"formulae"))formulae = f.readlines()
for i in range(0,len(formulae)):
formulae[i] = formulae[i].strip("\n")
f.close()
These lines load the formulae already found from the file. This is needed if I have to stop the code then want to continue.
python
oldlen = 0newlen = 26
while oldlen != newlen:
for f in formulae + variables:
candidate("-" + f)
for f in formulae + variables:
for g in formulae:
for star in ["I", "F", "N", "U"]:
candidate("(" + f + star + g + ")")
oldlen = newlen
newlen = len(formulae)
The code inside the while loop goes through every formula already found and puts "-" in front of it, then takes every pair of formulae already found and puts "I", "F", "N" or "U" between them. These characters are used instead of the logical symbols as using the unicode characters leads to numerous python errors. The candidate function as defined above then adds them to the list (if they are suitable). This continues until the loop does not make the list of formulae longer as this will occur when all formulae are found.
python
f = open(join(path,"formulae"),"a")f.write("#FINISHED#")
f.close()
Once the loop has finished this will add the string "#FINISHED#" to the file. This will tell the truth-checking code when the it has checked all the formulae (opposed to having checked all those generated so far).
Tautologies
Now that the above code is finding all formulae, I need to test which of these are tautologies. This can be done by checking whether every assignment of truth values to the variables will lead to the statement being true.
python
from os.path import joinpath = "/home/pi/logic"
First import any modules needed and set the path where the file will be saved.
python
def next(ar,i=0):global cont
if i < len(ar):
if ar[i] == "0":
ar[i] = "1"
else:
ar[i] = "0"
ar = next(ar, i + 1)
else:
cont = False
return ar
Given an assignment of truth values, this function will return the next assignment, setting cont to False if all the assignments have been tried.
python
def solve(lo):lo = lo.replace("-0", "1")
lo = lo.replace("-1", "0")
lo = lo.replace("(0I0)", "1")
lo = lo.replace("(0I1)", "1")
lo = lo.replace("(1I0)", "0")
lo = lo.replace("(1I1)", "1")
lo = lo.replace("(0F0)", "1")
lo = lo.replace("(0F1)", "0")
lo = lo.replace("(1F0)", "0")
lo = lo.replace("(1F1)", "1")
lo = lo.replace("(0N0)", "0")
lo = lo.replace("(0N1)", "0")
lo = lo.replace("(1N0)", "0")
lo = lo.replace("(1N1)", "1")
lo = lo.replace("(0U0)", "0")
lo = lo.replace("(0U1)", "1")
lo = lo.replace("(1U0)", "1")
lo = lo.replace("(1U1)", "1")
return lo
This function will replace all instances of "NOT TRUE" with "FALSE" and so on. It will be called repeatedly until a formula is reduced to true or false.
python
f = open(join(path,"formulae"))formulae = f.readlines()
f.close()
f = open(join(path,"donet"))
i = int(f.read())
f.close()
variables = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j",
"k", "l", "m", "n", "o", "p", "q", "r", "s", "t",
"u", "v", "w", "x", "y", "z", "@", "#", "2", "3",
"4", "5", "6", "7", "8", "9"]
These lines read the formulae from the file they are saved in and load how many have been checked if this script has been restarted. The the variables are set.
python
while formulae[-1] != "#FINISHED#" or i < len(formulae) - 1:if i < len(formulae):
formula = formulae[i].strip("\n")
These lines will loop through all formulae until "#FINISHED#" is reached.
python
insofar = TrueinA = []
fail = False
for a in variables:
if a not in formula:
insofar = False
elif not insofar:
fail = True
break
else:
inA.append(a)
Here, the code checks that if a variable is in the formula, then all the previous variables are in the formula. This will prevent the Twitter bot from repeating many tautologies that are the same except for the variable a being replaced by b (although there will still be some repeats like this. Can you work out what these will be?).
python
if not fail:valA = ["0"]*len(inA)
cont = True
taut = True
while cont and taut:
feval = formula
for j in range(0,len(inA)):
feval = feval.replace(inA[j],valA[j])
while feval not in ["0", "1"]:
feval = solve(feval)
if feval != "1":
taut = False
valA = next(valA)
if taut:
f = open(join(path,"true"),"a")
f.write(str(formula) + "\n")
f.close()
i += 1
f = open(join(path,"donet"),"w")
f.write(str(i))
f.close()
Now, the formula is tested to see if it is true for every assignment of truth values. If it is, it is added to the file containing tautologies. Then the number of formulae that have been checked is written to a file (in case the script is stopped then resumed).
python
else:f = open(join(path,"formulae"))
formulae = f.readlines()
f.close()
If the end of the formulae file is reached, then the file is re-loaded to include all the formulae found while this code was running.
Tweeting
Finally, I wrote a code that tweets the next item in the file full of tautologies every three hours (after replacing the characters with the correct unicode characters).
How long will it take?
Now that the bot is running, it is natural to ask how long it will take to tweet all the tautologies.
While it is possible to calculate the number of formulae with 140 characters or less, there is no way to predict how many of these will be tautologies without checking. However, the bot currently has over 13 years of tweets lines up. And all the tautologies so far are under 30 characters so there are a lot more to come...
Edit: Updated time left to tweet.
Edit: Added Mastodon and Bluesky links
(Click on one of these icons to react to this blog post)
You might also enjoy...



Comments
Comments in green were written by me. Comments in blue were not written by me.
In part two you say a_{n+4} >= 2*a_n, and you have 13 years worth of tweets of length (say) 15-30. so there are 26 years worth length 19-34 characters, 13*2^n years worth of tweets of length between (15 + 4n) and (30 + 4n). In particular, setting n = 27, we have 13*2^{27} = 1744830464 years worth of tweets of length 123-138. I hope you have nice sturdy hardware!
 ×3 ×3 ×3 ×3 ×3
×3 ×3 ×3 ×3 ×3
Christian
Add a Comment
2014-09-04
Last weekend, I attended Electromagnetic Field, a camp for hackers, geeks, makers and the interested. On the Sunday, I gave a talk on four mathematical ideas/tasks which I have encountered over the past few years: Flexagons, Folding Tube Maps, Braiding and Sine Curves. I'd love to see photos, hear stories, etc from anyone who tries these activities: either comment on here or tweet @mscroggs.
Flexagons
It's probably best to start by showing you what a flexagon is...
What you saw there is called a trihexaflexagon. Tri- because it has three faces; -hexa- because it is a hexagon; and -flexagon because it can be flexed to reveal the other faces.
The story goes that, in 1939, Arthur H. Stone, who was an Englishman studying mathematics at Princeton, was trimming the edges off his American paper to fit in his English folder. He was fiddling with the offcuts and found that if he folded the paper under itself in a loop, he could make a hexagon; and when this hexagon was folded up as we saw, it would open out to reveal a different face.
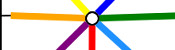
)
The way it flexes can be shown on a diagram: In the circles, the colour on either side of the flexagon is shown and the lines show flexes which can be made.
)
When Stone showed his flexagon to other students at Harvard, they were equally amazed by it, and they formed what they called 'The Flexagon Committee'. Members of the committee included Richard Feynman, who was then still a graduate student. The committee could meet regularly and soon discovered other flexagons, the first of which was the hexahexaflexagon: Again shaped like a hexagon, but this time with six faces.
)
A hexahexaflexagon is created by taking a longer strip of paper and rolling it around itself like this. The shorter strip at the end is then folded and glued in the same way the trihexaflexagon was. Once made, the hexahexaflexagon can be flexed. From some positions, the flexagon can be flexed in different ways to reveal different faces. Due to this, finding some of the faces can be quite difficult.
The committee went on to find other flexagons which could be made, again made by first folding into a shorter strip, then folding up like the trihexaflexagon.
The committee later found that hexaflexagons with any number of faces could be made by starting with a certain shaped strip, rolling it up then folding it like a trihexaflexagon.
Resources & further reading
An excellent article by Martin Gardner on flexagons can be found in this book.
Trihexaflexagon templates (click to enlarge then print):
)
)
Our second story starts with me sitting on the tube reading Alex's Adventures in Numberland by Alex Bellos on the tube. In his book, Alex describes how to fold a tetrahedron, or triangle-based pyramid, from two business cards. With no business cards to hand, I picked up two tube maps and followed the steps: first, I folded it corner to corner; then I folded the overlaps over.I made another one of these, but the second a mirror image of the first, slotted them together and I had my tetrahedron.
)
)
)
Then I made a tube map cube by making six squares like so and slotting them together.
)
)
)
While making these shapes, I discovered an advantage of tube maps over business cards: Due to the pages, folded tube maps have slots to tuck the tabs into, so the solids are pretty sturdy.
Making these shapes got me wondering: what other Platonic solids could I make?
In 2D, we have regular shapes: shapes with all the sides of the same length and all angles equal. Platonic solids are sort of the 3D equivalent of this: they are 3D shapes where every face is the same regular shape and at each vertex the same number of faces meet.
For example, our tetrahedron is a Platonic solid because every side is a regular triangle, and three triangles meet at every vertex. Our cube is a Platonic solid because every side is a square (which is a regular shape) and three squares meet at every vertex.
In order to fold all the Platonic solids, we must first find out how many there are.
To do this, we're going to start with a triangle, as it is the 2D shape with the smallest number of sides, and make Platonic solids.
If we try to put two triangles at each vertex, then they'll squash flat; so that's no good. We've seen that three triangles at each vertex makes a tetrahedron. If we put four triangles at each vertex then we get an octahedron.
)
Five triangles at each vertex gives us an icosahedron.
)
Each angles in an equilateral triangle is 60°. So if we put six triangles at each vertex the angles add up to 360°, a full turn. This means that the triangles will lie flat, giving us a nice pattern for a kitchen floor, but not a solid. Any more than 6 triangles will add up to more than 360 and also not give a solid. So we have found all the Platonic solids whose faces are triangles.
Next, four sided faces. Three squares at each vertex gives us a cube. Four squares at each vertex will add up to 4 times 90°... 360° again, so another kitchen floor and as before we have all the Platonic solids whose faces are squares.
Now moving up again to five sided faces. Three pentagons at each vertex will gives us a dodecahedron, which looks like this.
)
This is the best I could do.
(After the talk, I was shown a few better ways to fold pentagons. Watch this space for my attempts...) Now if we try four pentagons around a vertex: the internal angle in a pentagon is 108°. 4 times 108° is 432°. This is more than a full turn, so we don't get a solid.
Moving up again, if we take three hexagons we get another tessellation. Shapes with more than six sides will all have larger angles than this so three make more than a full turn.
Therefore, we have found and folded all the Platonic solids.
In 2012, I posted this on my blog and got the following comment:
)
I'm pretty sure this was a joke, but one hour, 48 tube maps and a lot of glue later:
)
Resources & further reading
Alex's Adventures in Numberland by Alex Bellos introduced business card folding and takes it further, finishing with a business card Menger sponge.
Braiding
A few months ago, my mother showed my a way to make braids using a cardboard octagon with a slot cut on each side and a hole in the middle.
)
To make a braid, seven strands of wool are tied together, fed through the hole, then one tucked into each slot.
)
Now, we jump over two strands, pick the third strand and move it to the vacant slot. So first, we jump over the orange and green and move the red strand.
)
Then we jump the light blue and yellow and move the dark blue.
)
And so on..
)
)
After a while, the braid looks like this:
)
Once I'd made a few braids, I began to wonder which other numbers of threads could be used to make braids like this. To investigate this I found it useful to represent braids by drawing connections to show where a thread is moved. This shows the first move:
)
Then the second move:
)
And so on until you get:
)
After the octagon, I tried braiding on a hexagon, moving the second thread each time. Here's what happened:
)
)
)
)
I only moved the yellow and green threads and nothing interesting happened. When I drew this out as before, it demonstrated what had gone wrong: three slots are missed so three threads are never moved.
)
So we need to find out when slots are missed and when all the slots are hit. To do this, let's call the number of slots \(a\), and let \(b\) be the number thread we pick each time. For example, in the first braid that worked \(a\) was 8 and \(b\) was 3.
First we'll label the slots. Label the slot which starts empty 0, then number anti-clockwise. This numbering puts all the multiples of \(a\) at the bottom slot.
Now let's look at which slots we visit. We start at0, then visit \(b\), then \(2b\), then \(3b\) and so on. We visit all the multiples of \(b\).
Therefore we will reach the bottom slot again and finish our loop when we reach a common multiple of \(a\) and \(b\). The first time this happens will be at the lowest common multiple, or:
$$\mbox{lcm}(a,b)$$
On our way to this slot, we visited one slot for every \(a\) we passed, so the number of slots we have visited is
$$\frac{\mbox{lcm}(a,b)}{a}$$
and we will visit every slot if
$$\frac{\mbox{lcm}(a,b)}{a}=b$$
or, equivalently if
$$\mbox{lcm}(a,b)=ab.$$
This is true when, \(a\) and \(b\) have no common factors, or in other words are coprime; which can be written
$$\mbox{hcf}(a,b)=1.$$
So we've found that if \(a\) is the number of slots and \(b\) is the jump then the braid will not work unless \(a\) and \(b\) are coprime.
For example, if \(a\) is 6 and \(b\) is 2 then 2 is a common factor so the braid fails. And, if \(a\) is 8 and \(b\) is 3 then there are no common factors and the braid works. And, if \(a\) is 12 and \(b\) is 5 then there are no common factors and the braid works.
But, if \(a\) is 5 and \(b\) is 2 then there are no common factors but the braid fails.
The rule I've explained is still correct, and explains why some braids fail. But if \(a\) and \(b\) are coprime, we need more rules to decide whether or not the braid works.
And that's as far as I've got, so I'm going to finish braiding with two open questions: Why does the 5 and 2 braid fail? And for which numbers \(a\) and \(b\) does the braid work?
Sine curves
For the last part of the talk, I did a practical demonstration of how to draw a sine curve using five people.
I told the first person to stand on the spot and the second person to stand one step away, hold a length of string and walk.
)
The third person was instructed to stay in line with the second person, while staying on a vertical line.
)
The fourth person was told to walk in a straight line at a constant speed.
)
And the fifth person had to stay in line with both the third and fourth people. This led them to trace a sine curve.
)
To explain why this is a sine curve, consider the following triangle:
)
As our first two people are one step apart, the hypotenuse of this triangle is 1. And so the opposite (vertical) side is equal to the sine of the angle.
I like to finish with a challenge, and this task leads nicely into two challenge questions:
1. How could you draw a cosine curve with five people?
2. How could you draw a tan(gent) curve with five people?
Resources & further reading
People Maths: Hidden Depths is full of this kind of dynamic task involving moving people.
(Click on one of these icons to react to this blog post)
You might also enjoy...

Comments
Comments in green were written by me. Comments in blue were not written by me.
Add a Comment
2014-06-21
With World Cup fever taking over, you may have forgotten that Wimbledon is just a few days away.
Tennis scoring
Tennis matches are split into sets (three sets for ladies' matches, five sets for men's), which are in turn split into games. The players take it in turns to serve for a game. The scoring in a game is probably best explained with a flowchart (click to enlarge):
)
To win a set, a player must win at least six games and two more games than their opponent. If the score reaches six games all, then a tie break is played. In this tie break, the first player to win at least seven points and two points more than their opponent wins. In the final set there is no tie break, so matches can last a long time.
Winning with the smallest share of points
Due to the way tennis is split into sets and games, the player who wins the most points will not necessarily win the match. This got me thinking: what is the smallest proportion of points which can be won while still winning the tennis match?
First, let's consider a men's match. In order to win with the lowest proportion of points, our player should let his opponent win two sets without winning a point and win the other three sets. In the two lost sets, the opponent should win 0-6 taking every point: in total the opponent will win 48 points in these sets.
Leaving the final set for now, the other two sets are won by our player. To win these with the smallest proportion of the points, they should be won 7-6 on a tie break. In the 6 lost games, the opponent should take all the points. In the won games and the tie break, our player should win by two points with the lowest total score. (Winning with more than the lowest total score will mean both players win an equal number of extra points, moving the proportion of points our player wins closer to 50%, higher than it needs to be.)
Therefore, our player will win 4 points out of 6 in the games he wins, win 0 out of 4 points in the games he loses and wins the tie break 7 points to 5. This means that in total our player will 62 points out of 144 in the two won sets.
For the same reason as above, the final set should be won with the lowest total score: 6-4. Using the same scores for each game, our player wins 24 points out of 52.
Overall, our player has won 86 points out of 244, a mere 35% of the points.
If the match is a ladies' match then the same analysis will work, but with each player winning one less set. This gives our player 55 points out of 148, 37% of the points.
This result demonstrates why tennis remains exciting through the whole match. The way tennis is split into sets and games means that our opponent can win 65% of the points but if the pressure gets to them at the most important points, our player can still win the match. This makes for a far more interesting competition than a simple race to one hundred points which could quickly become a foregone conclusion.
Comparing players with serving stats
During tennis matches, players are often compared using statistics such as the percentages of serves which are successful. Imagine a match between Player A and Player B.
In the first set, Player A and Player B are successful with 100% and 92% of their serves respectively. In the second set, these figures are 56% and 48%. Player A clearly looks to be the better server, as they have a higher percentage in each set. However if we look at the two sets in more detail:
| Player A | Player B | |
| First Set | 20/20 | 67/73 |
| Second Set | 45/80 | 13/27 |
| Total | 65/100 | 80/100 |
Table showing successful serves/total serves.
Overall, Player B has an 80% serve success rate, while Player A only manages 65%.
This is an example of Simpson's paradox: a trend which appears in the set-by-set data disappears when the data is combined. This occurs because when we look at the set-by-set percentages, the total number of serves is not taken into account: Player A served more in the second set so their overall percentage will be closer to 56%; Player B served more in the first set so their overall percentage will be closer to 92%.
(Click on one of these icons to react to this blog post)
You might also enjoy...




Comments
Comments in green were written by me. Comments in blue were not written by me.
Add a Comment